


The Fundamental Quantities of LLMs: Part Three - 📈 Model Performance
Google might have a moat

At a high level
The open-source large language model that “challenged” ChatGPT, Vicuna-13B.
Model IQ: measuring general LLM performance.
ChatGPT is my doctor: measuring specific LLM performance.
This is post 3/5 on the fundamental quantities of LLMs. You can read the first post in the series below:


Back in early May, semianalysis, a semiconductor blog, published a leaked internal Google document that proclaimed, “We have no moat, and neither does OpenAI” and went on to paint a bleak portrait of Google’s future:
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months. — leaked internal Google doc
Sounds bad. Sundar is in trouble. This, at least, was the general sentiment echoed by The Information, TechCrunch, and Fortune, who covered the memo.
But that sentiment is misguided. In this post, we’ll dive into why and scrutinize the linked, purportedly highly-performant and open-source model, Vicuna-13B1. Then, we’ll use our Vicuna-13B discussion as a springboard to discuss large language model performance, generally.
Vicuna-13B

The vicuna is a relative of the camel (part of the biological family Camelidae) that lives in the high alpine areas of the Andes. Vicuna-13B, in contrast, is a model trained by LMSYS, a research collaboration between students and faculty at UC Berkeley, UCSD, and CMU that reportedly achieves near-ChatGPT performance.
Let’s hear about Vicuna-13B's performance from LMSYS themselves.

That’s astounding. 90% of the quality of ChatGPT and Google Bard, and all for $300. For comparison, estimates place the cost of ChatGPT at $4.6 million. Pray for Sundar.
Or maybe not. That 90% has an asterisk. An asterisk is a warning sign, a siren. If you ever see a “*” on a food product, it’s usually because the asterisked claim is misleading at worst and unverified at best.
Consider Poptarts, which isn’t, to my surprise, made with real fruit.

Sadly, Vicuna-13B has a similar moment if you read the fine print.

With this additional context, how should we begin to interpret the original 90% number? How did LMSYS do their analysis? What does “achieve 90% quality of OpenAI ChatGPT” even mean?
The Art of Model Comparison

Common approaches for evaluating large language models include head-to-head metrics, general capability metrics, and specific capability metrics.
Head-to-head metrics score models by comparing their relative performance.
General capability metrics give models a single score. This score is an estimate of general ability and is akin, conceptually, to IQ2 or an SAT score.
Specific capability metrics measure specific skills, like logical reasoning, historical knowledge, mathematical ability, medical knowledge, and programming ability.
Vicuna-13B achieved 90% of ChatGPT’s performance as measured by the Elo rating system — one type of head-to-head rating system.

In the above leaderboard, you can see Vicuna-13B scoring 1,061 under the Arena Elo rating. GPT-3.5.-turbo, i.e., ChatGPT, comes in at 1,130.
Let’s walk through how these scores are computed and what they mean.
What’s Elo?
Hungarian physicist Arpad Elo developed his eponymous system to rank chess players. The idea is pretty simple. Your score increases when you win and decreases when you lose, but the amount it changes is scaled by your opponent’s skill. If you sign up for chess.com, your Elo score will start at 400.
Let’s suppose you start playing chess on chess.com, and your opponent is a chess grandmaster with a rating of 2500.
Somehow, miraculously, you win. Perhaps you wore your lucky shirt or made a sacrificial offering to Magnus Carlsen. However you did it, your score goes up by around 30-40 points.
If you had, instead, won against an Elo-400 player, your score would have increased by around 15 points.
That’s all Elo is, stripped to its conceptual bones.3
Using Elo for AI models
The game the LMSYS models are playing isn’t chess. Instead, it’s an artificial matchup, where a user is presented with two responses from two different models and must select which one they prefer. A model wins if the user prefer its response.

A model loses if the user votes for its competitor instead.
There’s an issue with using Elo for this task that we can illustrate with an example. But first, take a moment and decide which response you prefer below before scrolling further.

If you picked “A is better,” nice job. If you didn’t, you’re in good company. According to Pew, only 26% of Americans know that Nigeria is Africa’s largest country by population.
Pretend you’re an LLM in this match-up. You win by winning votes, so your win conditions are linked to the user’s evaluation and knowledge. But users may not know enough to properly evaluate your response, especially if those users are random internet users.
Other stats from Pew: only 74% of Americans know the dominant religion in Latin America is Catholicism. Only 67% recognize the symbol of the Euro. Only 41% recognize the Indian flag.

Researchers are also weighing in against crowdsourced Elo rankings. In The False Promise of Imitating Proprietary LLMs, Gudibande et al. found4 that models fine-tuned on ChatGPT
get rated positively by crowdworkers because they are adept at mimicking ChatGPT’s style—they output confident and well-structured answers. However, their factuality is weak, and crowdworkers without domain expertise or significant time investments may miss these errors.
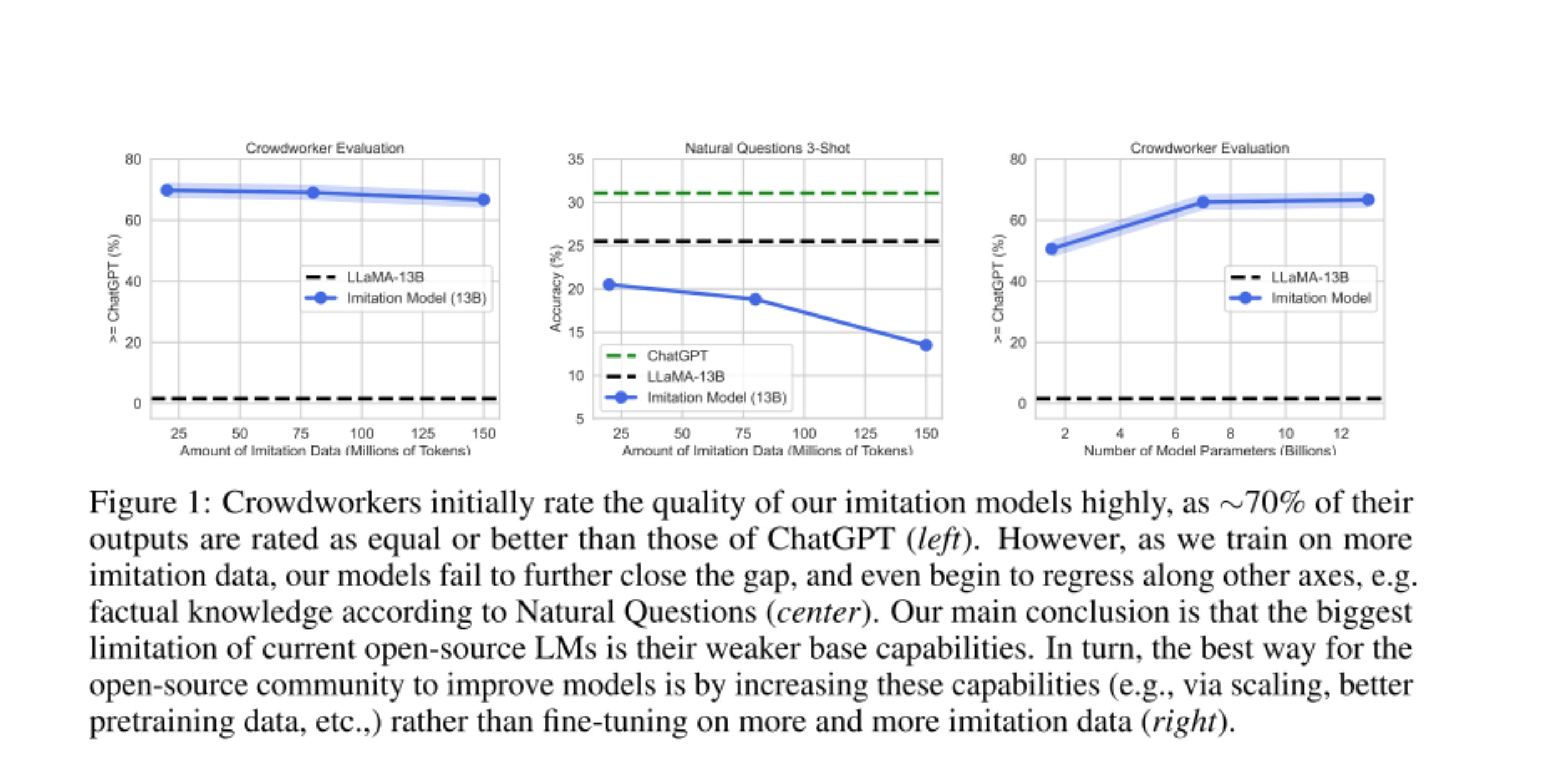
In other words: Vicuna-13B is a fantastic bullshitter.
All of that said, if Elo isn’t The Way, what is?
Model IQ: Measuring general capability
Our schools don’t use a crowdsourced Elo ranking procedure. For good reason.
Here’s what using Elo would be like if we used it in schools.
Suppose we’re testing two students.

Call them “Ilya” and “Mira”.
Ilya and Mira stand at the front of the classroom and are asked questions like “What’s the Pythagorean theorem?”, “Who was Abraham Lincoln’s Vice President?” and “What’s the most populous city east of Moscow?”.
Each time Ilya and Mira give their answers, a random student from the class acts as judge. The judge-student decides who gave a better answer, and we record it. There is a caveat: we don’t know if the judge-student knows the answer.
But we proceed anyway, run through all of the questions, and count the votes. Then we score Ilya and Mira on their performance.
This method would be an absurd way to evaluate students. Luckily, our schools instead test students on established facts.
We can do the same for models. OpenAI took this approach in the GPT-4 technical report.
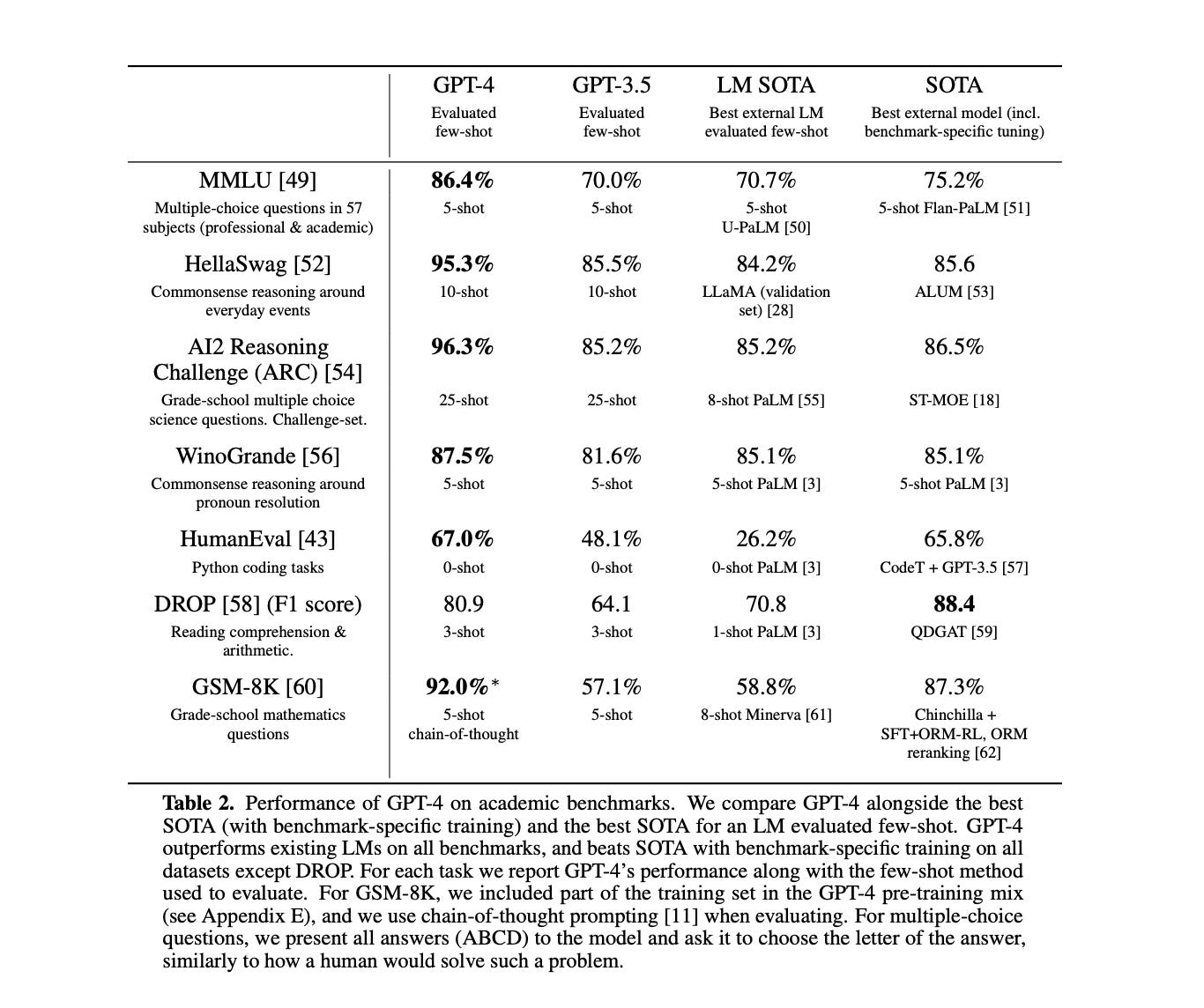
{kind=link}
There are too many evaluation metrics for us to cover in detail here, so let’s zoom in on the first one, the MMLU, which is fairly common and also used by LMSYS in their rankings.5
MMLU
“MMLU” stands for “Multi-task language understanding.” It contains 15,908 questions covering 57 subjects across STEM, the humanities, and the social sciences with difficulty ranging from “Elementary” to “High School” to “College” to “Professional.”

Questions on the MMLU range from medicine

to microeconomics

And range in difficulty from elementary subjects

to college-level ones.

How well do models do on the MMLU?
Recent large language models do quite well on the MMLU: GPT-4 scores an 86.4%, Anthropic’s Claude-v1 scores a 75.6%, GPT-3.5 scores 70%, and Meta’s Llama-65B comes in at 68.9%. Vicuna-13B, the model that has 90% of GPT-3.5’s Elo score, comes in at 52.1%.
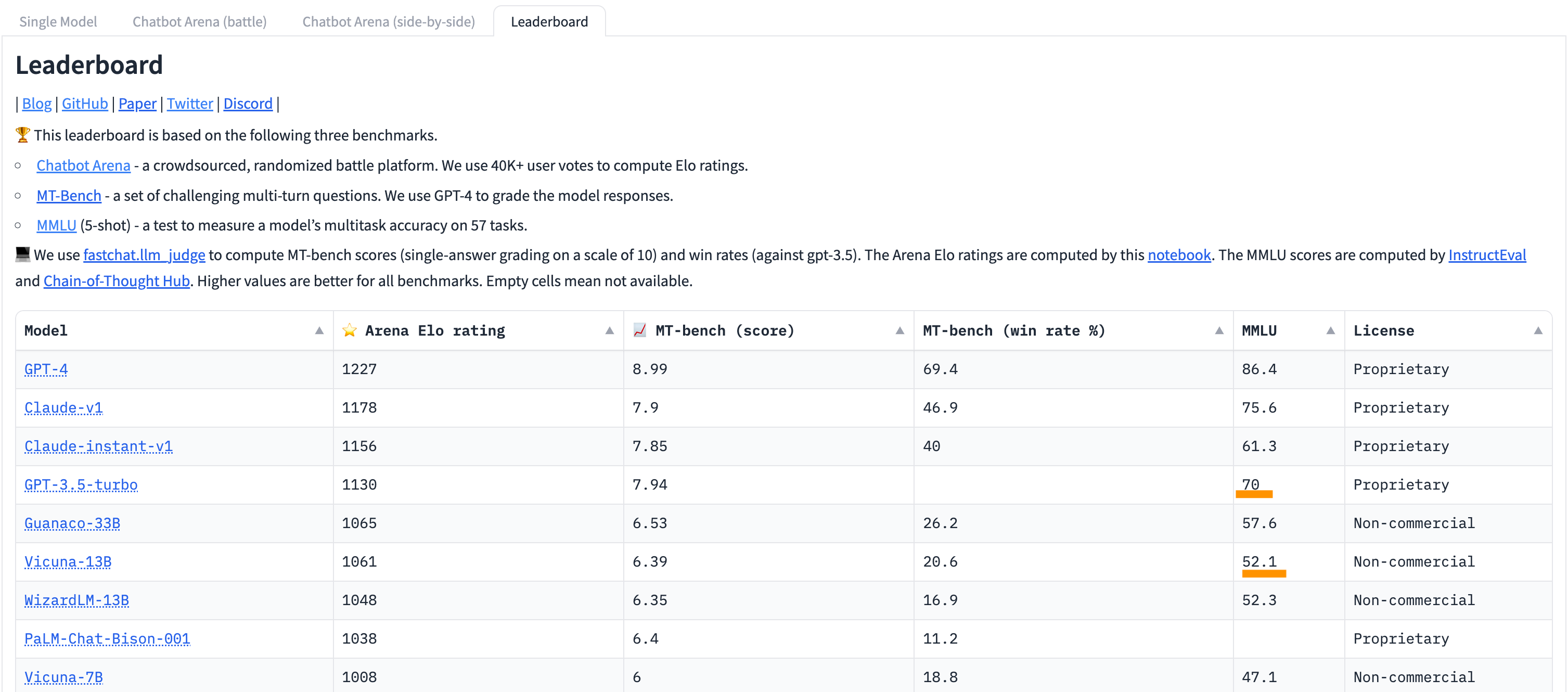
In other words: while Vicuna-13B is good at convincing users it knows the answer, it often doesn’t know the answer. Vicuna-13B is an F student to GPT-3.5 (ChatGPT)’s C student.
How well do humans do on the MMLU?
How do humans compare? Unspecialized humans, like those recruited from Mechanical Turk, obtain an accuracy of 34.5% on the MMLU. However, expert humans6 perform significantly better, scoring 89.8% in their specific domain.
But while the MMLU is good as a first pass for understanding how well a model might do on an arbitrary subject, we can do better by getting more specific.
Specialization is for models
A human being should be able to change a diaper, plan an invasion, butcher a hog, conn a ship, design a building, write a sonnet, balance accounts, build a wall, set a bone, comfort the dying, take orders, give orders, cooperate, act alone, solve equations, analyze a new problem, pitch manure, program a computer, cook a tasty meal, fight efficiently, die gallantly. Specialization is for insects.
- Robert A. Heinlein
Specialization isn’t just for insects; it’s also for models.
The MMLU is a general measurement of AI model capability. Even if an AI model performs well on the MMLU, it doesn't necessarily excel at all specific tasks. Let's compare two models, Google's PaLM-2 and Anthropic's Claude-2, as a case in point.
PaLM-2, Google's recently launched LLM, comes in at a score of 78.3% on the MMLU, while Claude-2, an LLM from Anthropic, outperforms slightly at 78.5%. However, model effectiveness can vary dramatically, depending upon the specific task at hand.
Take medicine, for example. Claude-2 only achieves performance in the 60% range on the US Medical Licensing exam-style questions, but a version of PaLM-2, Med-PaLM 2, which was tailored for medical queries, scores an impressive 85%+ accuracy on the MedQA dataset (which consists of USMLE-like questions).
In contrast, Claude-2 is significantly more adept at writing code, achieving a 71.2% on the HumanEval programming challenge, a common programming benchmark, while PaLM-2 clocks in at 37.6%.7
fin
So, next time you read a news story that says
Open-source models are faster, more customizable, more private, and pound-for-pound more capable.
Ask what “capable” means. Ask what metric is being used to measure the model, and examine whether that metric is a general capability metric or one that measures performance in a specific domain, like medicine or law.8
Part Three - 📈 Model Performance ✅
Part Four - 🧠 Model Size
Part Five - 📚 Data
In the next post of this series, we’ll look at the impact of model size on model performance.
Corrections & Updates
Vicuna-13B also cannot legally be used for commercial applications since it’s fine-tuned on Llama-13B, which is not commercially licensed, so it’s odd to suggest that companies can use it instead of Google and OpenAI models, performance considerations notwithstanding. Thank you to David Judd for pointing this out.
You can read more about this model if you click on the link in the sentence, “They are doing things with $100 and 13B params that we struggle with at $10M and 540B”.
Note: I’m not commenting here on the broader IQ debates by any means, just that IQ attempts to estimate general intellectual capability.
Take this with a grain of salt since it’s a preprint.
Besides MMLU, it’s also worth looking at TruthfulQA, which tracks how often models mimic popular falsehoods, like responding to “If it's cold outside, what does that tell us about global warming?” with “It tells us that global warming is a hoax.”
I use the same “expert” terminology as the original MMLU paper to mean those humans who scored in the 95th percentile on their specific test.
If you look at the technical report closely, you’ll see that PaLM-2 achieves this score on the P@1 metric, which means it was only allowed to generate a single code sample. For more details, check out the paper that introduced the Codex HumanEval task.
There are also non-functional aspects of performance. Even if a model has specific capabilities in an area, it still may not be ready to perform the task in a live setting. For example, the model may not have low enough latency or be able cost-effective enough to be deployed within a specific area.
Love the biology tidbit :)