
The Fundamental Quantities of LLMs: Part One - 📜 What are Large Language Models?
a few key machine learning concepts for a non-technical audience

This is the first post in a five-part series covering how to measure and compare large language models. By the end of this series, you will have a toolkit for comparing different large language models using four dimensions that we’ll cover over the next four posts:
Part Four - 🧠 Model Size
Part Five - 📚 Data
By the end of this series, you will also understand the “large” in “large language models,” why OpenAI needed to raise an eye-popping $10 billion from Microsoft (the 🖥️ Compute post), why an internal document from Google frantically discusses the looming possibility of open-source lapping them with smaller and cheaper models (the 📈 Model Performance post), and why platforms like Stack Overflow and Reddit are charging for data (the 📚 Data post).
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months. — leaked internal Google doc
And you will have a sense of why scale matters.
What are large language models?
Machine learning models1 do two things: they learn, and they infer. We’ll cover both learning, otherwise known as “training,” and inference.
We’ll do this via a cooking metaphor and then inspect the actual task that large language models perform: next-word prediction.
To begin, let's tackle one of the most challenging parts: defining LLMs clearly with minimal jargon.
What are LLMs?
A large language model (LLM) is a neural network with billions of parameters that has been trained to predict the next word using large quantities of unlabeled text data.
There are two terms in this definition that merit explanation.2
neural network: a neural network is a type of computer program that's designed to mimic the way the human brain works, with the goal of learning from data. For more details, check out this excellent explainer video from 3Blue1Brown.
parameter: a parameter in a neural network is a variable that is internal to the model. Its value is not predetermined but is estimated or learned from the data during the training process.
So, just as a chef might adjust the amount of salt based on taste, a neural network adjusts its parameters based on the data it's learning from, trying to make its predictions as accurate as possible.
Now let’s consider this culinary metaphor in full by thinking through how we’d train ourselves to cook a personalized yellow curry recipe.
Nine-Parameter Curry

Training
Learning to cook a Thai Yellow Curry involves adjusting numerous parameters: the choice of protein (like chicken, tofu, or shrimp), the amount and type of vegetables, the quantity of yellow curry paste, the volume of coconut milk, the level of spiciness, the simmering time, the amount of fish sauce or salt, and the quantity of sugar.
Your goal in making the curry is simple and hedonistic: taste and flavor. How you achieve your goal isn’t quite clear, so for your first attempt, you start with the following:
1 lb chicken breast, cut into bite-sized pieces (protein parameter)
2 tablespoons vegetable oil (oil parameter)
3 tablespoons Thai yellow curry paste (curry paste parameter)
1 can (13.5 oz) coconut milk (coconut milk parameter)
1 cup diced bell pepper (bell pepper parameter)
1 cup diced onion (onion parameter)
2 teaspoons fish sauce (fish sauce parameter)
1 teaspoon sugar (sugar parameter)
2 red Thai chilies, finely chopped (spiciness parameter)
This “nine-parameter curry” is your starting point. Each parameter is a knob you can tune. You can alter anything in the recipe: the sugar, the chilies, the curry paste. You can tweak the amount of chicken or coconut milk. However, since there are many possible combinations of parameters, you cannot try them all.
Since your time is limited, you cook your curry five times.
Iteration One
You cook the curry as written. You plate it, take a bite, and realize it tastes bland.
You give the curry a score of 6 out of 10.
Iteration Two
6 out of 10 isn’t good enough. Not for you. But before you start cooking again, you stop and ask yourself, “How quickly do I want to adjust my recipe?”.
Some cooks make large changes to their recipes. They might double the chilies or halve the coconut milk, taking on larger risks for larger rewards. However, this could lead to overshooting the optimal flavor profile, resulting in a dish that is far too spicy or not creamy enough.
We call the size of the changes you make to your recipe each time you cook it the learning rate.
Other cooks prefer to use a smaller learning rate, making smaller, more careful adjustments. You decide to be conservative since you don’t want to risk ruining your curry. You add only half a chili more and reduce the coconut milk by a tenth of a cup. This is a smaller learning rate. It might mean slower progress, but it also reduces the chance of overshooting your target and ruining the dish.
After your adjustment, you taste it and give the curry a score of 7.2, detecting a slight improvement.
Iteration Three
You suspect you’re on the right path, but the curry still isn’t spicy enough, so you again make another set of tiny adjustments. You again add 1/2 a chili and decrease the coconut milk by 0.1 cups.
You taste this version and give it a score of 7.4. Moving in this direction is definitely improving the curry.
Iteration Four
You repeat your step. You add 1/2 a chili and decrease coconut milk by 0.1 cups. The score jumps to 7.5.
Iteration Five
For your final attempt, you again add 1/2 a chili for a total of four chilis but notice the curry has become too spicy, so you revert to your recipe from iteration four of 3.5 chilis and call it a day.

This is your favorite version of your curry so far, and you don’t think you can do any better, so you “freeze” your parameters as follows:
1 lb chicken breast, cut into bite-sized pieces (protein parameter)
2 tablespoons vegetable oil (oil parameter)
3 tablespoons Thai yellow curry paste (curry paste parameter)
1.3875 cups of coconut milk (coconut milk parameter)
1 cup diced bell pepper (vegetable parameter)
1 cup diced onion (vegetable parameter)
2 teaspoons fish sauce (fish sauce parameter)
1 teaspoon sugar (sugar parameter)
3.5 red Thai chilies, finely chopped (spiciness parameter)
This is your recipe. You’ve optimized your curry parameters.3
Inference
Now that you've perfected your curry parameters, you're ready to share it with others and adapt it to new situations. You invite friends over for dinner and begin cooking your Thai Yellow Curry with the exact same parameters you've fixed above: protein, vegetable oil, coconut milk, curry paste, fish sauce, etc.
But just before you add the coconut milk, your friend Dennis mentions that he’s developed a taste for creamier curries. You want Dennis to have a good time, so you adapt your recipe to accommodate his preference while still maintaining the flavor profile.
Since you've already trained your curry parameters, you can confidently make a prediction about how to adjust the recipe even though you’ve never cooked a curry before with this same level of creaminess and spiciness4. You decide to increase the amount of coconut milk and adjust the number of chilis accordingly to maintain spiciness.
This process of using the learned parameters to make predictions based on data is called “inference.” In this case, you inferred how to alter your recipe to accommodate your friend's preference for a creamier curry while still delivering a flavorful dish.
LLMs aren’t chefs: predicting the next word

Now that we’ve talked through training and inference using curry, we’ll talk about the exact training task for large language models.
Training
Training a large language model is like optimizing 9-parameter curry, except instead of optimizing how much you enjoy your curry, the model optimizes how well it can predict the next token5 in a sentence.6
Imagine I give you the following sentence, and you guess what token goes in the blank:
"the capital of the United States is _"
You'd likely guess "Washington D.C."
Now if I give you the sentence:
“the capital of New Zealand is _”
You might guess “Auckland” and get it wrong (it’s Wellington).
Now that you know it’s Wellington, the next time I ask you for the capital of New Zealand or to complete related sentences, you’ll do better. You have learned.
Big data for big parameters
When it comes to large language models, we feed them billions of sentences like these, tell them where they made mistakes, and the models tweak their parameters to decrease their error rate.
The sentences number in the billions because there are many parameters to adjust. More parameters mean more flexibility, i.e., the model is more expressive, but more parameters also mean we have more unknowns to estimate. This is why we need more data.
Imagine cooking a curry with a billion parameters. In order to get the best parameter settings for your curry, you’d probably have to cook it billions of times, if not more. It’s the same with predicting the next token in a sentence. That’s why we need so many training iterations and so much data.
“Just train it”

Suppose we gather our billion sentences, load the model onto a compute cluster, and kick off the training process. We wait around, and after enough time has passed, we check the model and see that it does a good enough job at predicting the next word.
The model, like in the curry example, is now ready for inference.
Inference
During the inference stage, LLMs use their learned parameters to make predictions based on their input data. You know this “input data” by another name — “the prompt.”
The prompt serves as a starting point for the model's output. For example, if the task is to generate a continuation of a story, the prompt might be the first few sentences of the story. If the task is to answer a question, the prompt would be the question itself.7
Once the LLM has the prompt, it generates the output one token at a time.
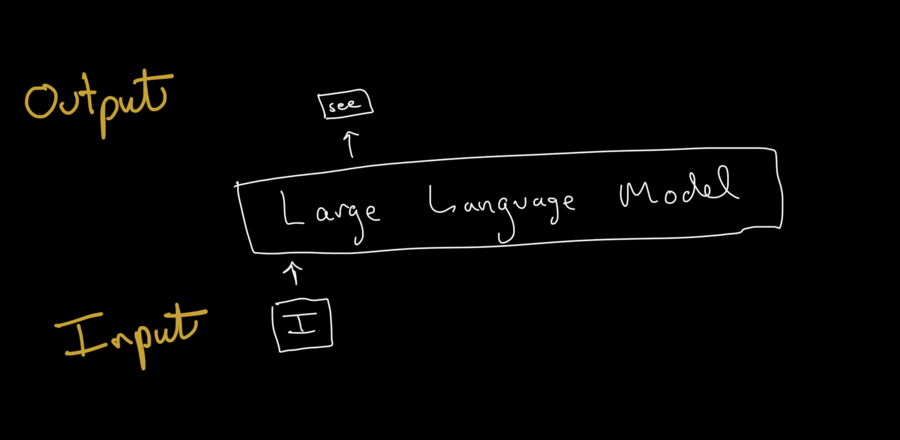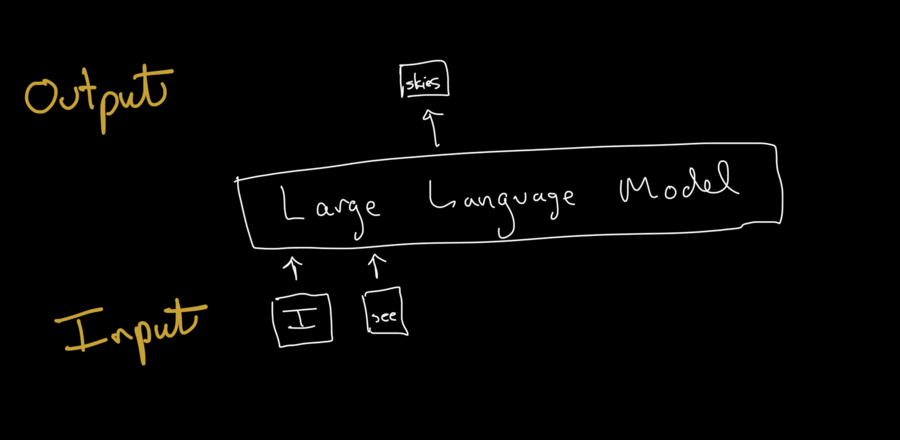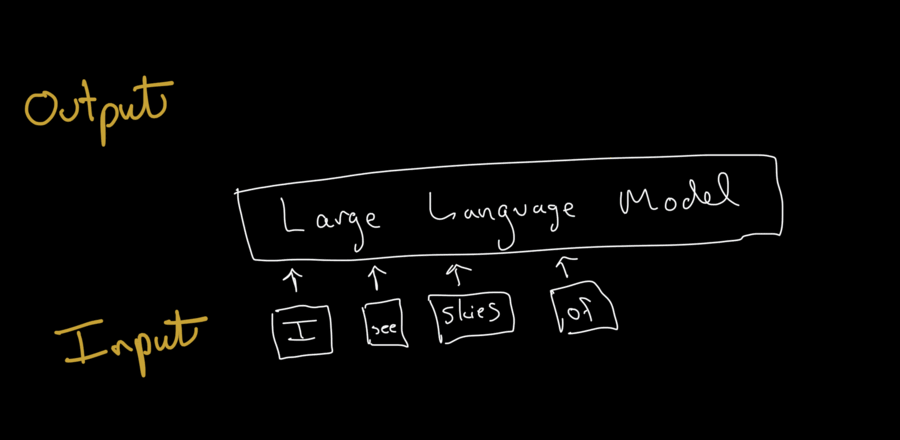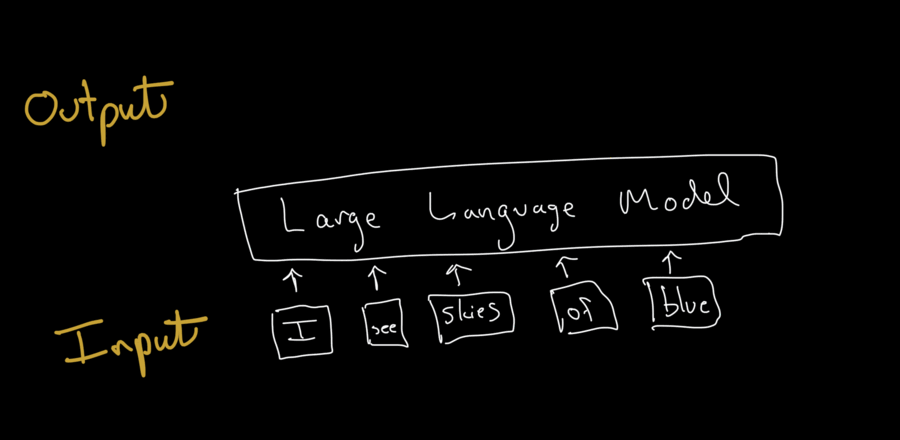
How does the model generate the text? It uses the parameters it learned during training to calculate the probabilities of the next token in the sequence based on the prompt and any tokens it has already generated.
The sky is _

To make this more concrete, let's consider a simple and hypothetical situation where we ask the model to predict the next token in the following sentence:
The sky is _
This sentence is what we feed into the model as the initial prompt. After processing, the model produces a probability distribution over the possible next tokens. Even though the model's vocabulary is extensive, including tens of thousands of tokens, let's simplify this scenario by considering only a few probable tokens:
"blue" with a probability of 0.5
"clear" with a probability of 0.3
"dark" with a probability of 0.1
"falling" with a probability of 0.05
"infinite" with a probability of 0.05
These probabilities symbolize the model's estimate of the likelihood of each token following the phrase, "The sky is".
Visualize these probabilities as creating a custom die. The more likely a word, the more faces that word “owns” on the die. In our example, "blue" has the most faces, followed by "clear", and so forth.
When the model "rolls" this custom die to decide the next token, "blue" is the most probable outcome due to its larger number of faces. However, any of the tokens could potentially emerge, introducing an element of non-determinism8 into the text generation process, leading to diverse output. After a word is selected, the process starts again, with the model recalculating probabilities based on the new sentence context.
Imagine the die lands on the token "blue". The model takes the token and appends it to the current sentence context. Now we have:
The sky is blue _
Now the model reworks the faces of the die so that the probabilities are now the probabilities for “the sky is blue” rather than “the sky is.” Then it rolls the die once more to predict the next token. It keeps this dynamic process alive, rolling and recalibrating until it either reaches a predefined limit9 or generates a token that signifies the end of the sentence or paragraph.10
Generating the next _
So there you have it. We’ve covered parameters, training, and inference. There’s further complexity that we’ll cover in the next few posts. For one thing, training a model like GPT-3 takes billions of iterations, and on a single machine, this process wouldn’t finish before 2100, if not later, so many machines need to be used.
In the next post, we’ll look at compute and cover why companies need so many computers for training, why training LLMs from scratch will likely remain a task for those with abundant capital, and why OpenAI raised $10 billion.
Technically, this applies to supervised machine learning models.
The above LLM definition is slightly simplified. Some language models are trained using “masking.” Masking is when given a segment of text like "I like to [MASK] [MASK] cream" the model predicts the masked tokens, like "eat ice".
This is simplified for the purposes of explanation. In a real optimization setting, we’d perform this procedure across all of the curry parameters.
If you ever cook with talented chefs, you’ll notice that they excel at this kind of improvisation.
For now, think of a token as a word. This is a simplification that we’ll expand on in a future post. That said, if you’re feeling impatient, check out this explainer.
If you read more technical literature, you’ll see these models referred to as "Autoregressive," which in the context of large language models refers to a model that generates sequences based on previous elements in the sequence. In other words, it predicts the next item in a sequence (like a word in a sentence) based on the previous items.
If you try this with ChatGPT, you’ll notice that ChatGPT doesn’t straightforwardly use the probability estimates from its training set as its probabilities during inference. This is because ChatGPT has had a process called “Reinforcement Learning from Human Feedback” (RLHF) applied to it, which we’ll cover in a future post.
You can test this non-determinism yourself by opening two separate and fresh ChatGPT windows and feeding them the same exact prompt. You’ll likely get different responses. Note that while ChatGPT has this decoding strategy, other language models might differ. If you want to learn more, Cohere has a nice explanation of decoding strategies.
If you’ve ever used the OpenAI API, you’ve likely encountered gpt-3.5-turbo hitting its 4,096 token limit.
This is known as an “end of sequence” (EOS) token.